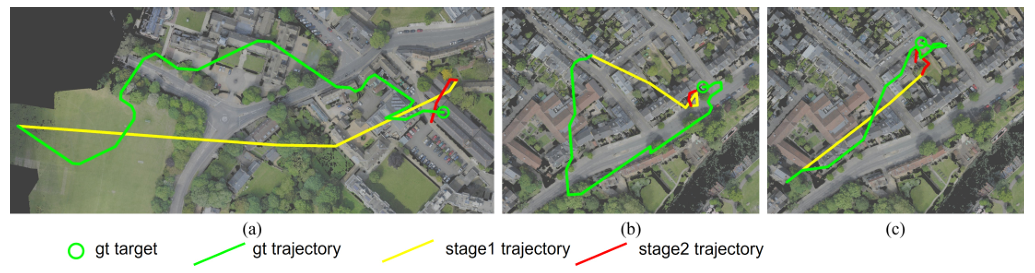
Abstract
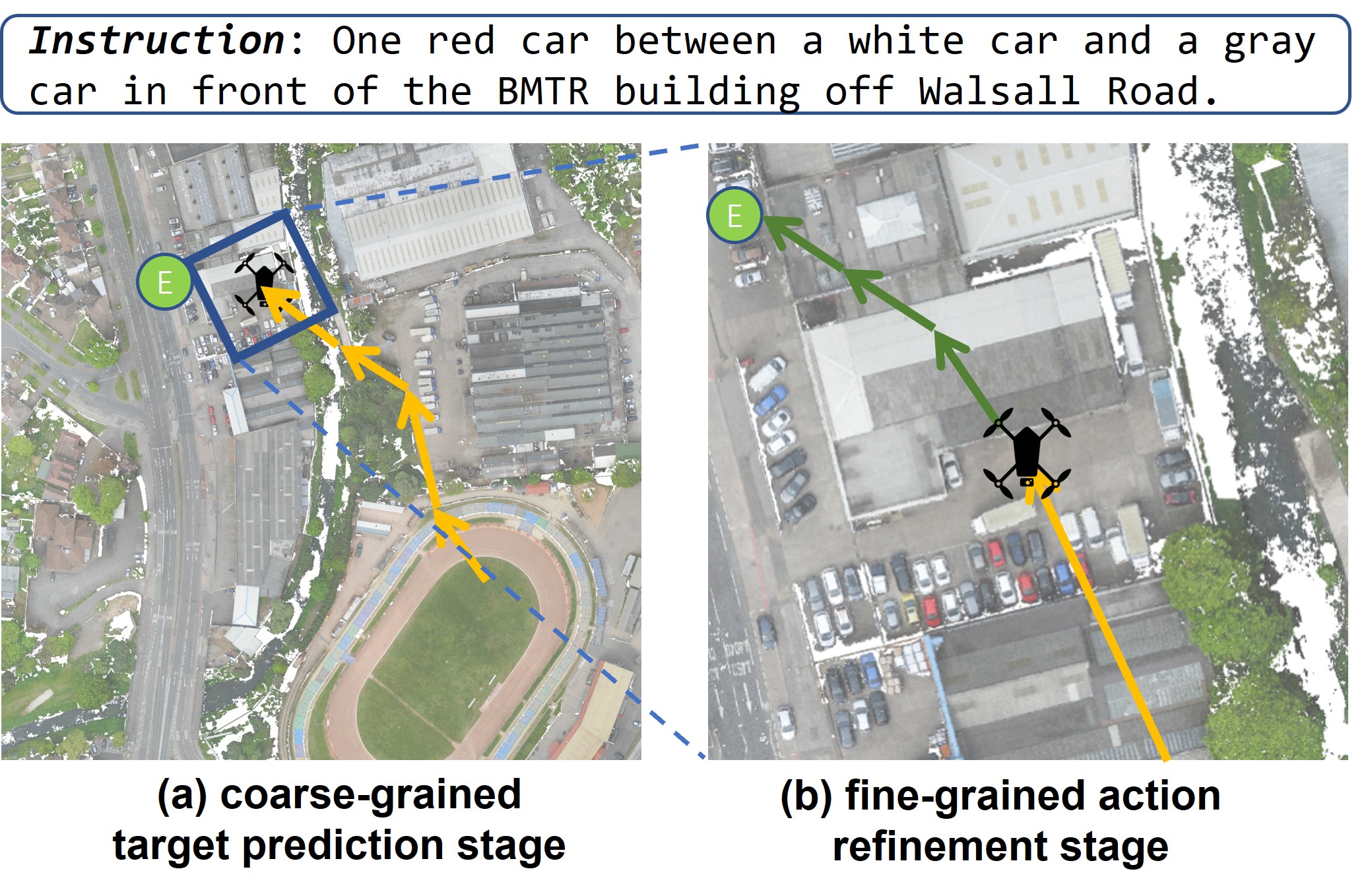
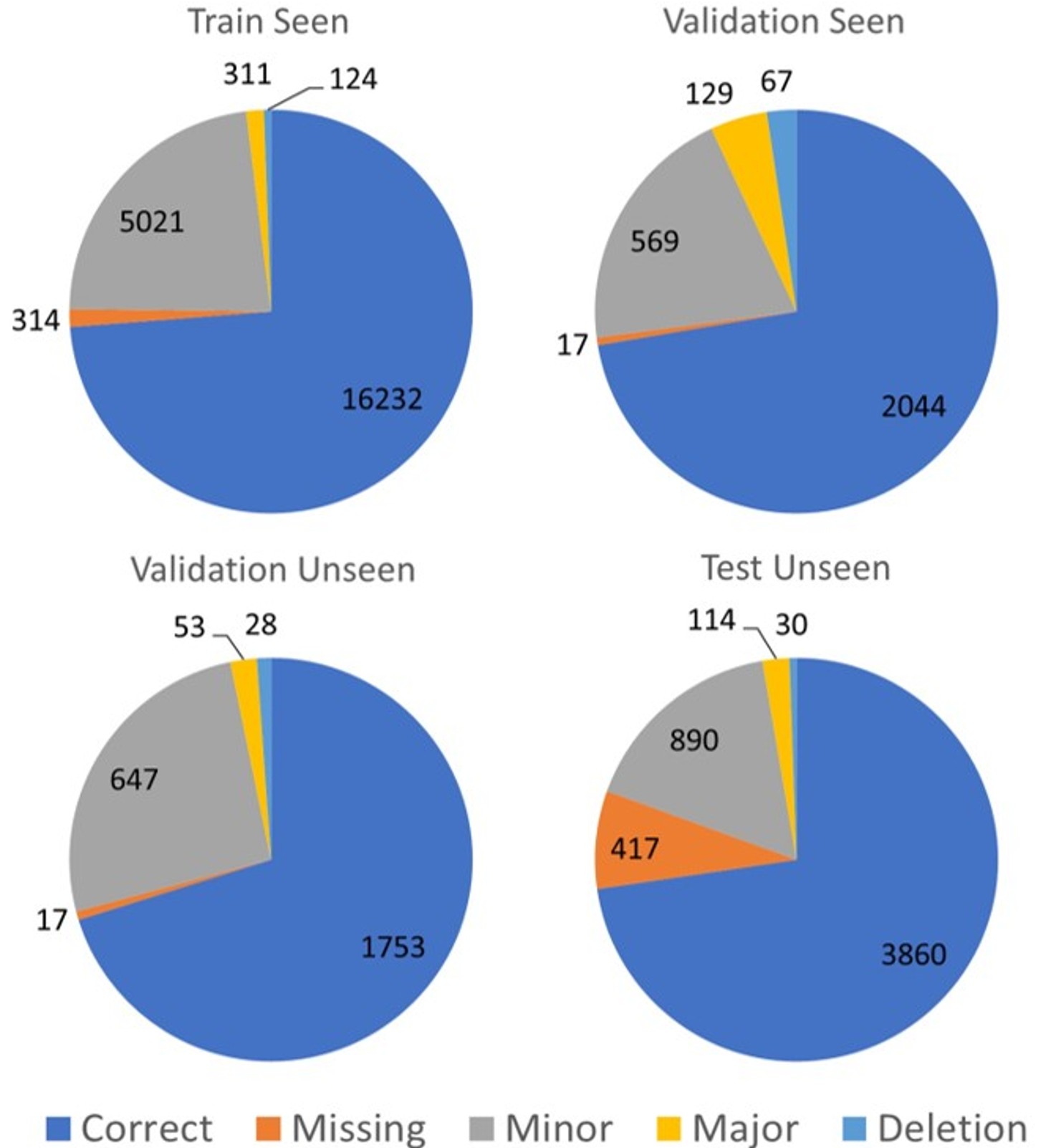
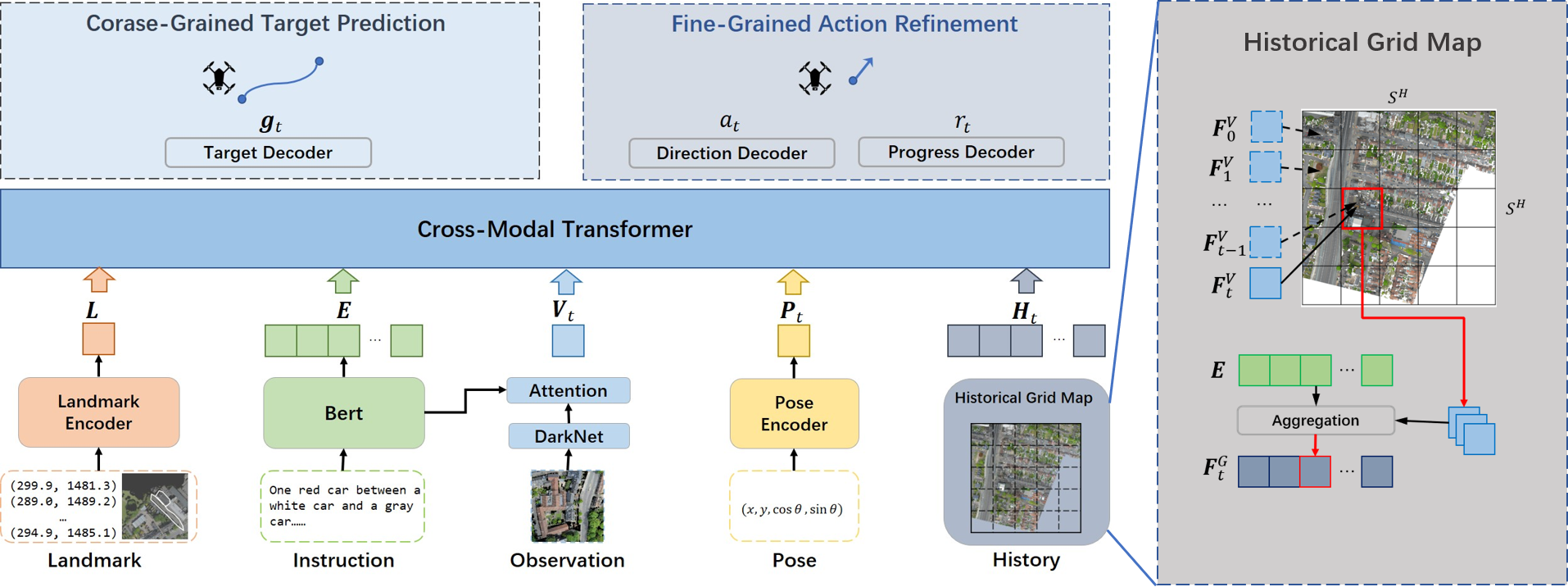
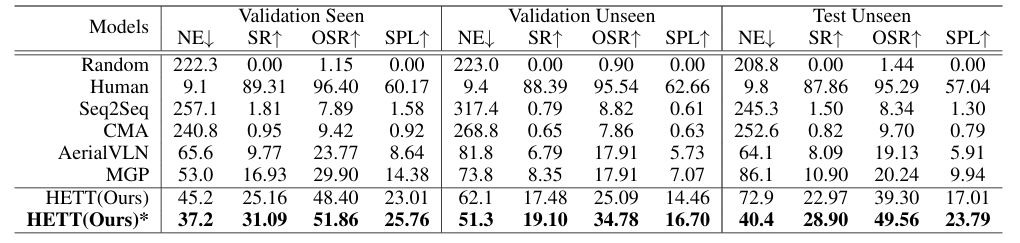
Aerial Vision-and-Language Navigation (AVLN) requires Unmanned Aerial Vehicle (UAV) agents to localize targets in large-scale urban environments based on linguistic instructions. While successful navigation demands both global environmental reasoning and local scene comprehension, existing UAV agents typically adopt mono-granularity frameworks that struggle to balance these two aspects. To address this limitation, this work proposes a History-Enhanced Two-Stage Transformer (HETT) framework, which integrates the two aspects through a coarse-to-fine navigation pipeline. Specifically, HETT first predicts coarse-grained target positions by fusing spatial landmarks and historical context, then refines actions via fine-grained visual analysis. In addition, a historical grid map is designed to dynamically aggregate visual features into a structured spatial memory, enhancing comprehensive scene awareness. Additionally, the CityNav dataset annotations are manually refined to enhance data quality. Experiments on the refined CityNav dataset show that HETT delivers significant performance gains, while extensive ablation studies further verify the effectiveness of each component.
Paper
BibTeX
@article{HETT2026,
title={History-Enhanced Two-Stage Transformer for Aerial Vision-and-Language Navigation},
volume={40},
url={https://ojs.aaai.org/index.php/AAAI/article/view/38885},
DOI={10.1609/aaai.v40i22.38885},
number={22},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Ding, Xichen and Gao, Jianzhe and Pan, Cong and Wang, wenguan and Qin, Jie},
year={2026},
month={Mar.},
pages={18225-18233}
}